


July 1, 2026
Celebrating 250 Years of American Maritime Strength




Catching Smugglers

What’s inside?
Shipping has underpinned international trade for millennia. Even today, more than 90% of world trade travels by sea, everything from coal to cobalt to cars. Of the hundreds of thousands of vessels out there, only a handful are involved in illicit activities. They do so because the economic incentives for, say, smuggling are enormous. The challenges these ships pose to security and enforcement agencies are similarly huge.
That’s because despite new technologies, tracking and monitoring global ship movements remains tricky. Yet, with proper analysis and maritime domain expertise, we can use this data to build highly-predictive anomaly-detection tools.
To do this, we first had to build a comprehensive database of vessels previously caught smuggling. From the cases our analysts investigated, we compiled thousands of examples of ships that operated anomalously and followed known smuggling routes and methods. Combined with records of vessels apprehended by the authorities, we used this data as the foundation for our predictive model.
Of course, we also had to create a “safe” sample i.e. vessels that were not involved in smuggling. This is arguably just as important as the selection of the “risky” sample. Each of our data points is a vessel at a certain point in time, so the “safe” samples have to follow this structure as well. The key factor we considered here was that we wanted the algorithm to be trained on a sample that was as close as possible to being a true representation of the “real world” the model will be used to analyze later. So we selected a set of “safe” vessels that are similar to a suspicious vessel in almost every respect, and that would control for bias in our workflow. The location in time and space was the same. The size of this sample represented the proportion of risky vessels we believe are out there. It was critical that this semi-random subsample be a good representation of safe vessels.
Using a ship’s location history, there are many parameters we can use to tell a vessel’s story. From the ports and docks visited by the ship we can learn more about what the ship does and the cargo it carries. Routes sailed and cruising speed are indicative of the efficiency of the operation. When a vessel abandons its regular routes and arrives in an area it has never visited before it could be considered a risk indicator. Many additional parameters can be relevant to assess the risk a ship poses, such as unusual changes in course, transshipments outside of known hubs, or turning off transmissions. The machine learning model we’ve created uses dozens of such features to predict in real time which vessels are more likely to be involved in smuggling.
For example, there’s the case of the ship that was boarded by the Greek coastguard in the Mediterranean. It was caught smuggling oil from Algeria to Crete. Examining the dynamic risk ranking our algorithm assigned to it over time shows that it spiked one month prior to the event (see below). Six days before being boarded, the ship was in the top 1% of vessels ranked by risk.
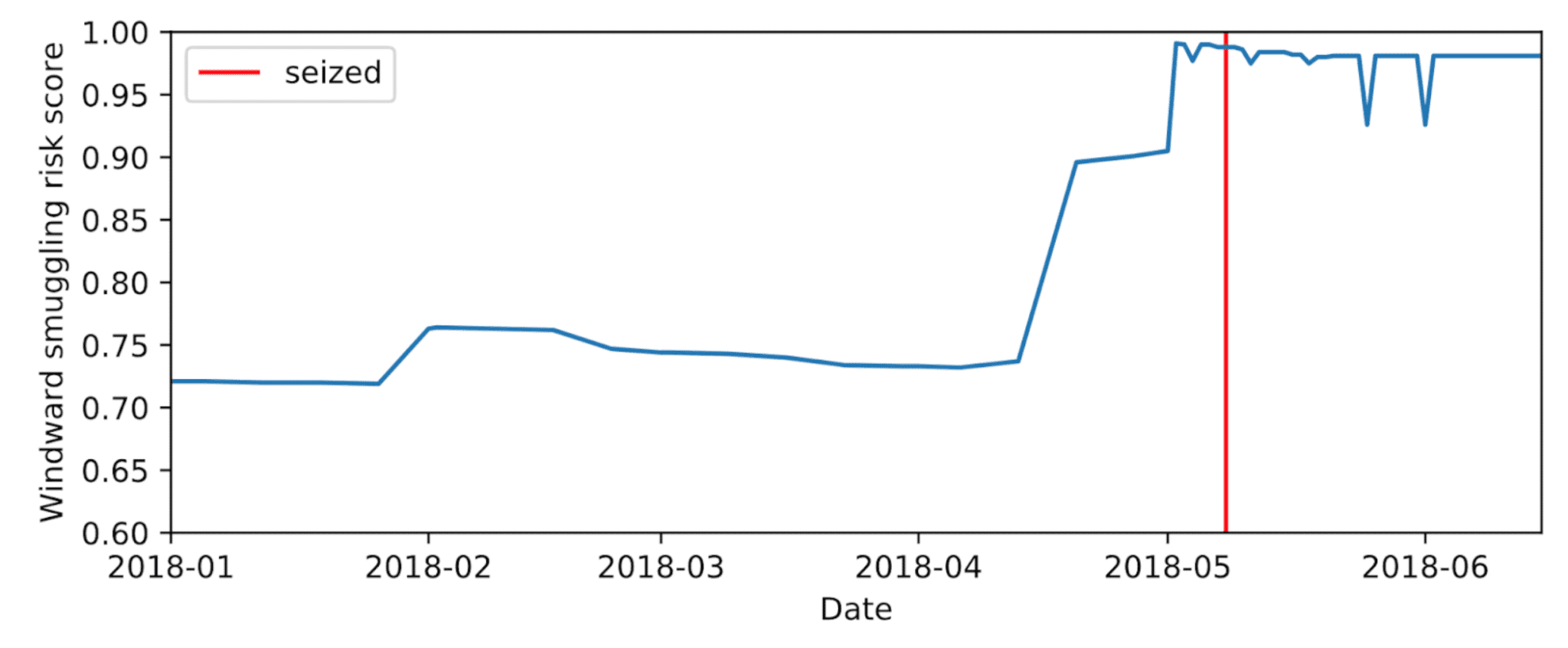
The prediction was heavily influenced by the vessel entering Algeria and Tunisia for the first time. In fact, this tanker began operating in an entirely new way in the weeks prior to being arrested, changing its whole areas and methods of operation. It also changed its name and other identifiers shortly before its ill-fated voyage. These features (and a couple of dozen more) caused a spike in the risk score this vessel received, just before it engaged in illicit activity
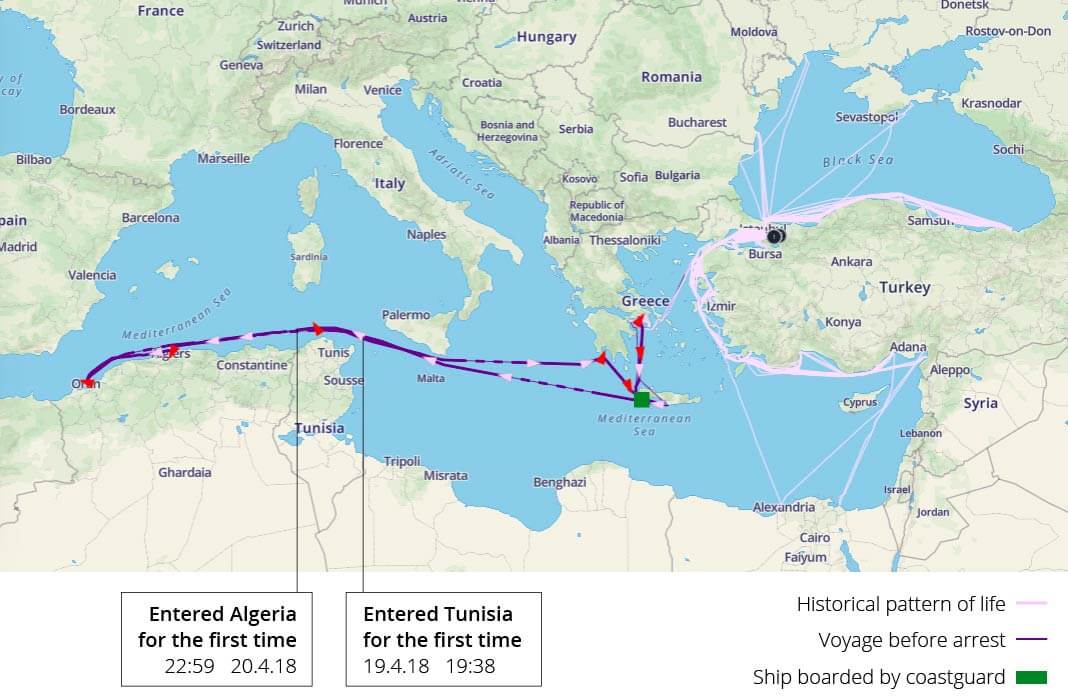
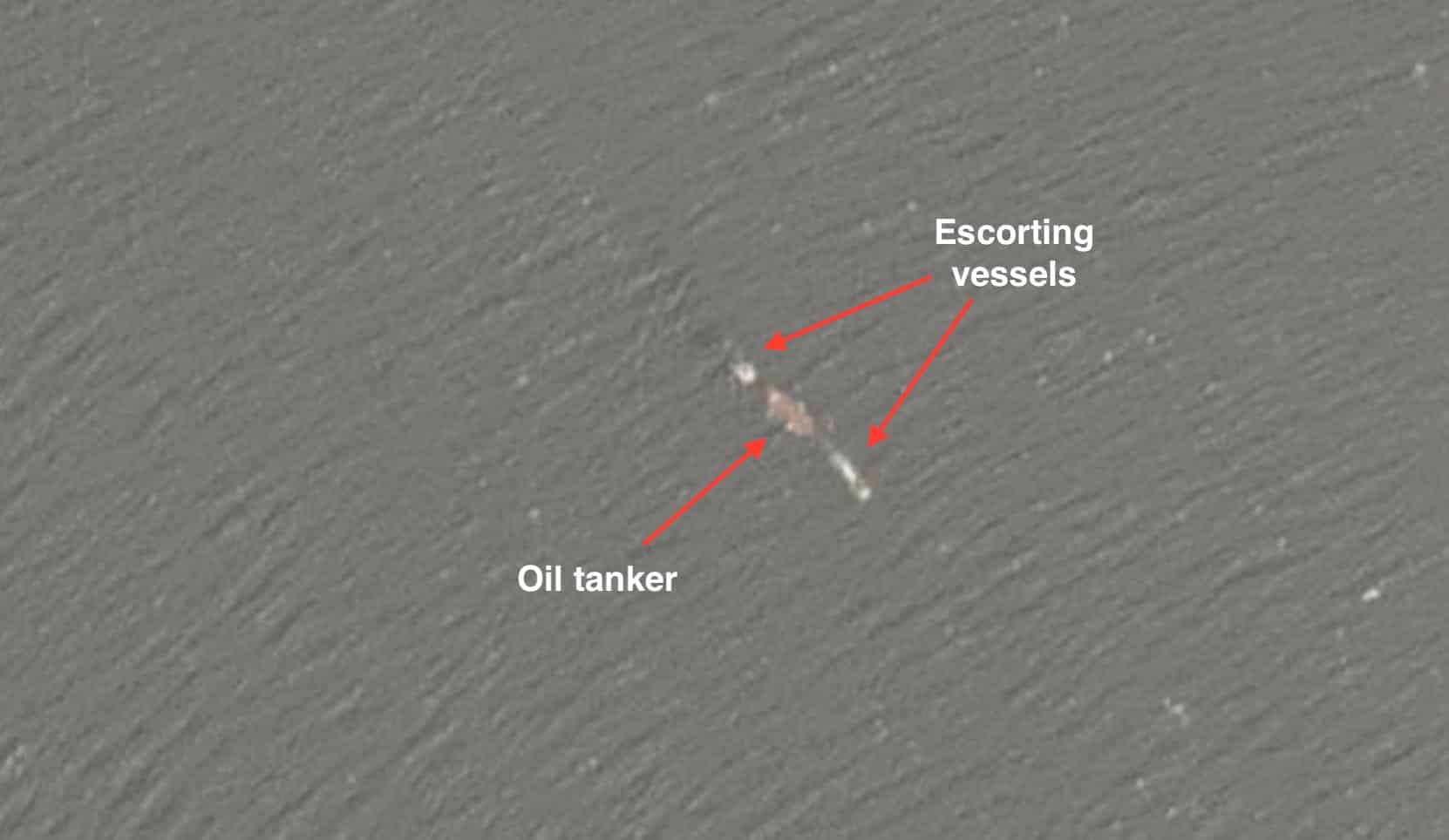
These kinds of predictions assist agencies such as coastguards, navies, customs authorities and other security organizations in prioritizing their resources, such as ships or human analysts. The true power of statistical prediction is in pointing the operator in the right direction, allowing them to focus on relevant anomalous cases and cut out all the noise.
Ohad Balaga is a Data Scientist at Windward
Explore more

Introducing GPS Jamming Resilience: Cutting False Vessel Activity From Contested Waters
Windward is releasing GPS Jamming Resilience, a new platform capability that automatically identifies and suppresses the false vessel activity generated by GPS interference, before any of it reaches an analyst. It launches already proven. Since Operation Epic Fury began in late February, the capability has filtered more than 2.2 million false ship-to-ship (STS) meeting records...
Read More

Ground Truth: Windward’s 2026 Commitment to Verified Maritime Intelligence
By Ariel Zibziner, VP Business Services, Windward Data Integrity in an Era of High-Frequency Signal Manipulation As we conclude 2025, the maritime domain is characterized by a trust deficit in digital signaling. The convergence of major global conflicts — continued hostilities in Ukraine, Houthi attacks disrupting Red Sea transit, suspected infrastructure sabotage in the Baltic,...
Read More

Windward Launches WhatsApp Integration for Instant Risk Insights
At a Glance Redefining Vessel Screening for a Real-Time World In global trade and shipping, decisions are rarely made from behind a desk. A call from port control, a sudden request from a counterpart, or a time-sensitive deal can trigger the need for immediate screening. Whether it’s a compliance check to prevent sanctions breaches or...
Read More

Navigate 2025’s Maritime Risk Landscape with Maritime AI™ at London International Shipping Week
As the global shipping community gathers for London International Shipping Week (LISW) 2025, one reality stands out: disruption is the operating environment, not the exception. The maritime ecosystem is under sustained pressure, and adapting to this high risk era is now a prerequisite for business continuity. From sanctions and signal interference to fraudulent documents and...
Read More

AI-Automated Document Validation: Streamlining Trade Against Real Maritime Activity
Global trade still runs on paper. Bills of Lading, certificates of origin, price attestations, and other documents remain the backbone of maritime trade, yet also its most persistent Achilles’ heel. Forged paperwork fuels fraud, delays compliance, and stalls cargo worth millions. Windward’s new AI-Automated Document Validation changes that, by cross-checking every document against what actually...
Read More